Marvelous Tips About How To Check Duplicates In A Table

Single Vs Duplicate Checksthe Difference Between And

Do I Need Duplicate Checks
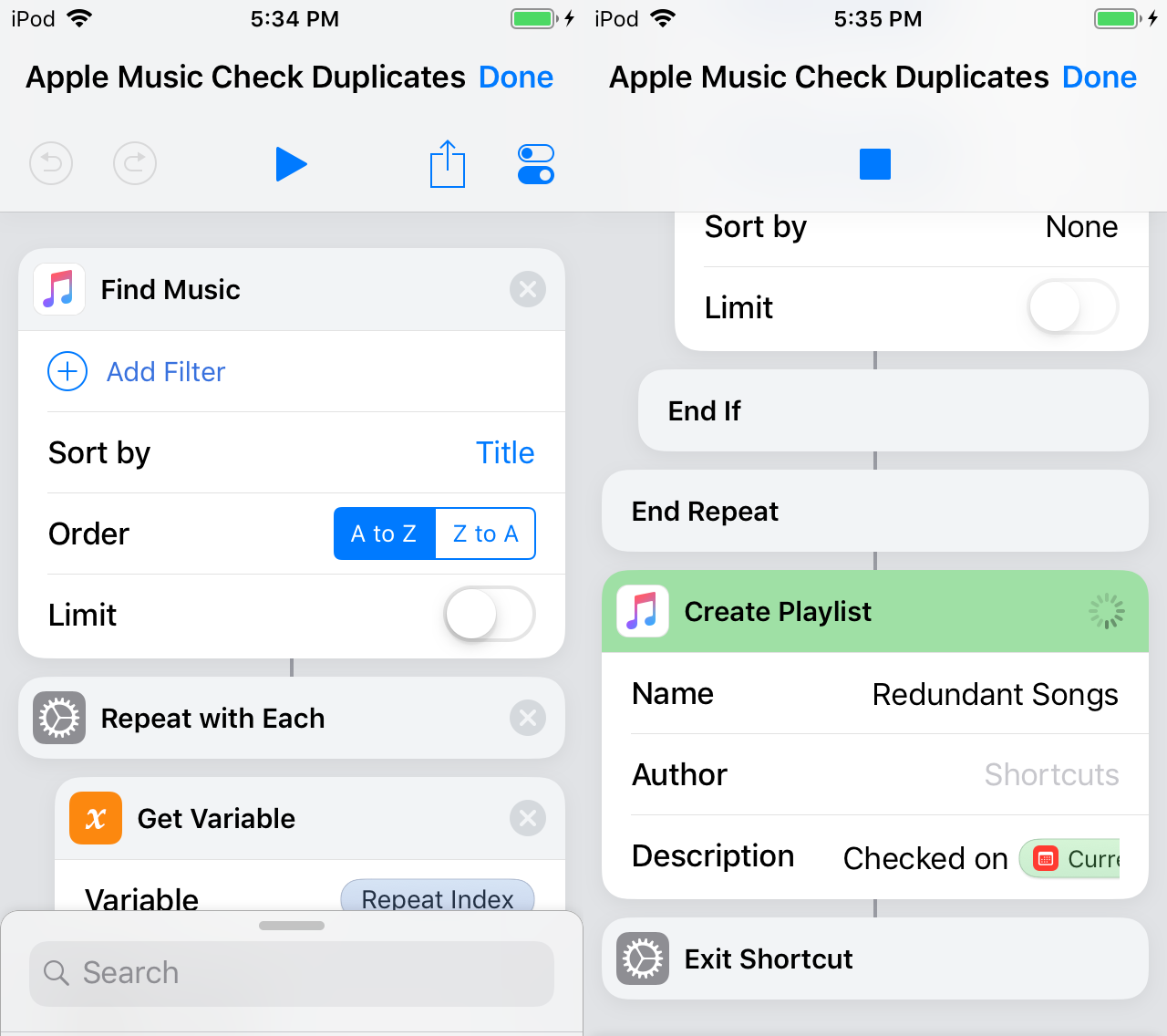
Check Items For Duplicates Better World By Software
Central Innovation
.png)
Remove The Duplicates From Pagelist Using Data Transform. Support
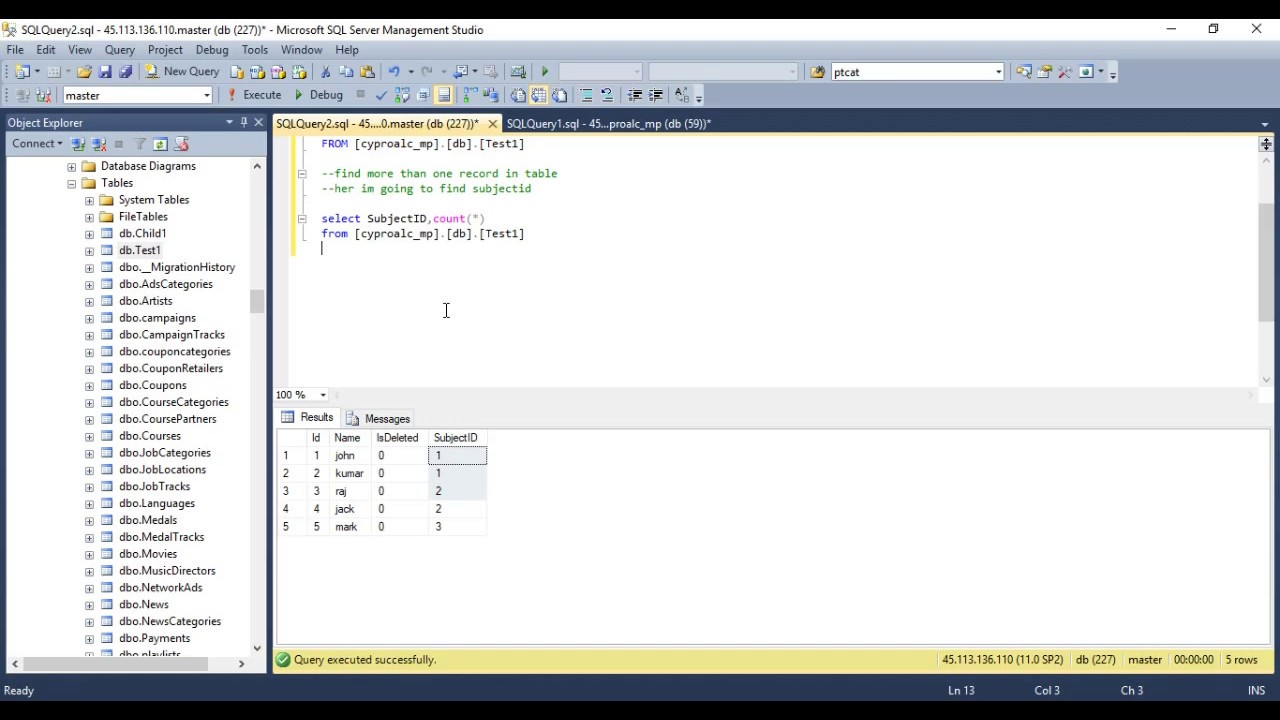
Finding Duplicate Values In A Sql Table Youtube
We can use this function to number each row in the table where the.
How to check duplicates in a table. To find duplicate rows from the fruits table, you first list the fruit name and color columns in both select and group by clauses. Select any cell within your table and click the dedupe table button on the excel ribbon. Do you need a combination of two columns to be unique together, or are you simply searching for duplicates in a single.
In this article, we will see how to write sql queries to get duplicate values from two tables. We can perform the given task using two methods: Values in a single column or multiple columns.
To find the duplicate names in the table, we have to follow these steps: One way this feature can be used is to display duplicates. At first, you need to define the criteria for finding the duplicate.
The most important thing here is to have the fastest function. In the examples below, we will be exploring both these scenarios using a simple. Access queries simple queries find duplicate records with a query find duplicate records with a query access for microsoft 365 access 2021 access 2019 access 2016 access.
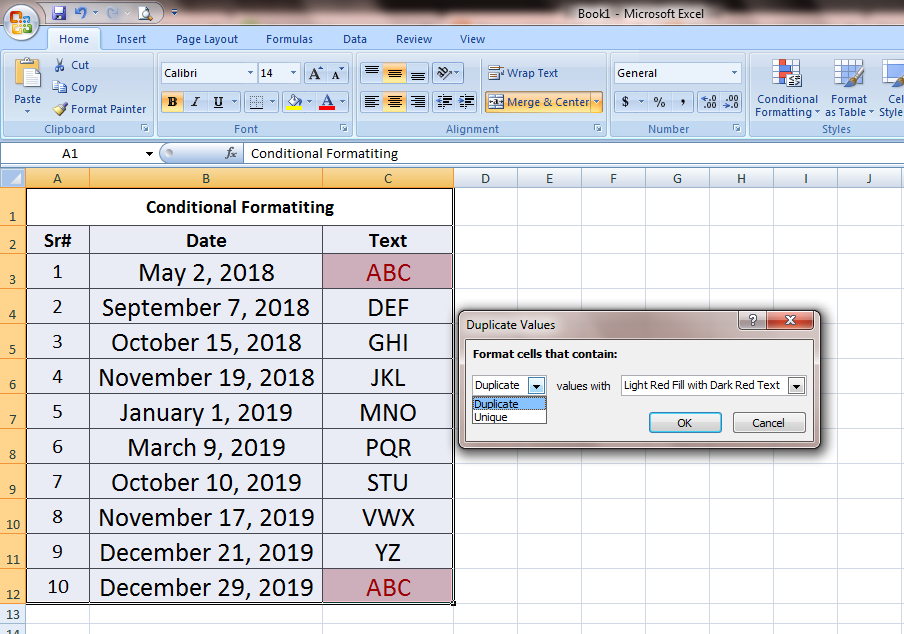
The first step is to define your criteria for a duplicate row. In the example shown, a pivot table is used to show duplicate cities in an excel table that contains more than 250. The first two rows are duplicates, and the last three rows are duplicates.
760 the key is to rewrite this query so that it can be used as a subquery. Removing duplicates from table without a unique index in oracle. First, you will need to define the criteria for detecting duplicate rows.
Also indices of duplicates should be identified. Another way to search for duplicate values is to use the row_number window function. To find the duplicate values in a table, you follow these steps:
Then you count the number of appearances. The following query will display all dewey decimal numbers that have been duplicated in the book table: By “duplicate rows” i mean two or more rows that share exactly the same values across all.
Self join is a good option but to have a faster function it is better to. First, use the group by clause to group all rows by the target column, which is the column that you. Is it a combination of two or more columns where you want to detect duplicate values, or are you simply searching for duplicates within a single column?
We need to find duplicates with a combination of first name and last name. First, define criteria for duplicates: Select * from yourtable ou where (select count(*) from yourtable inr where inr.sid = ou.sid) > 1 you can adjust the where clause in the inner query to narrow the search.
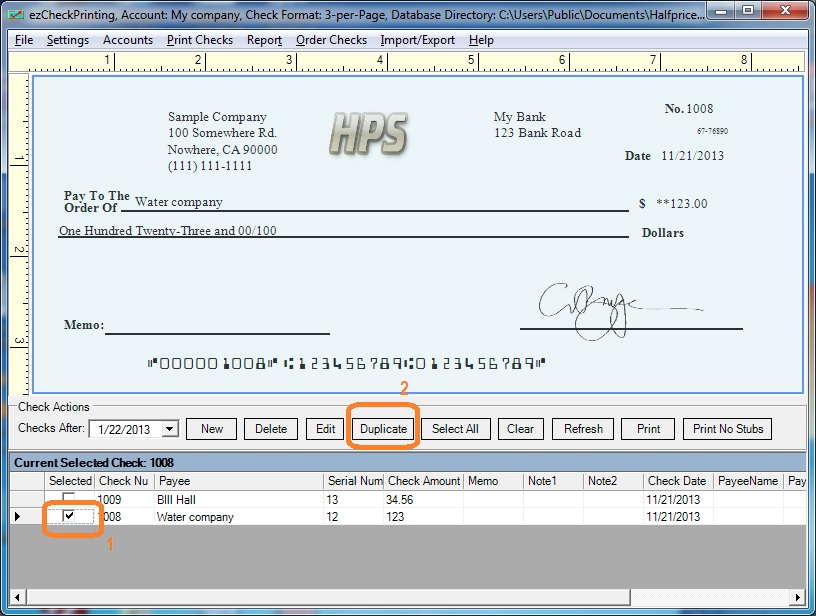
How To Print Recurring Checks

How To Check Duplicates In Google Sheets Filedrop

Quick Check For Duplicates In Your Salesforce Marketing Database
![[Solved] How to check for duplicates in mysql table over 9to5Answer](https://sgp1.digitaloceanspaces.com/ffh-space-01/9to5answer/uploads/post/avatar/88050/template_how-to-check-for-duplicates-in-mysql-table-over-multiple-columns20220601-1957786-8u6qgo.jpg)
[solved] How To Check For Duplicates In Mysql Table Over 9to5answer
How To Find Duplicates In Excel Technology Magazine
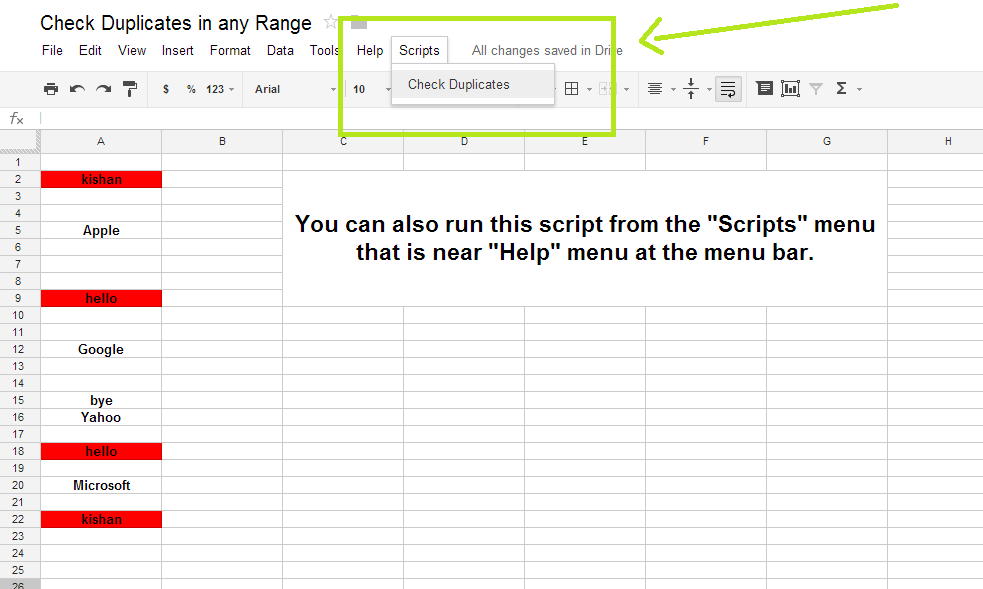
Igoogledrive Google Spreadsheet How To Check Duplicates In Any Range
![How to Find and Highlight Duplicates in Google Sheets [The Easiest Way]](https://8020sheets.com/wp-content/uploads/2021/07/Duplicates-1-914x1024.png)
How To Find And Highlight Duplicates In Google Sheets [the Easiest Way]
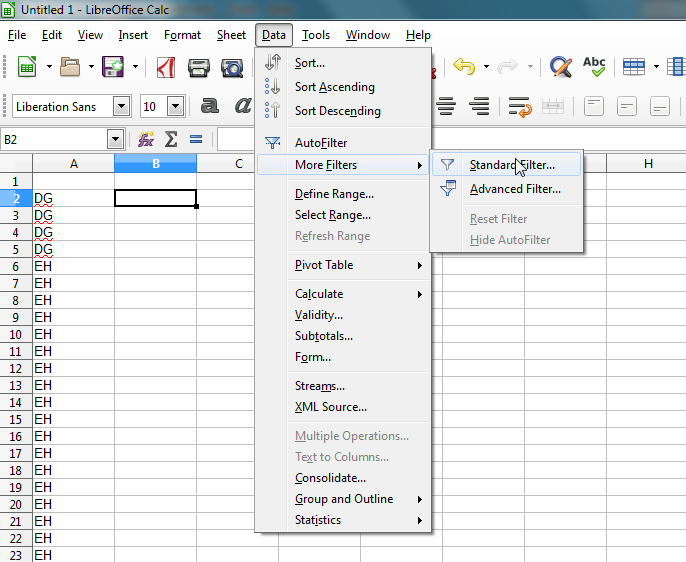
Removing Duplicates From A List Using Libreoffice Anna F J Smith Morris

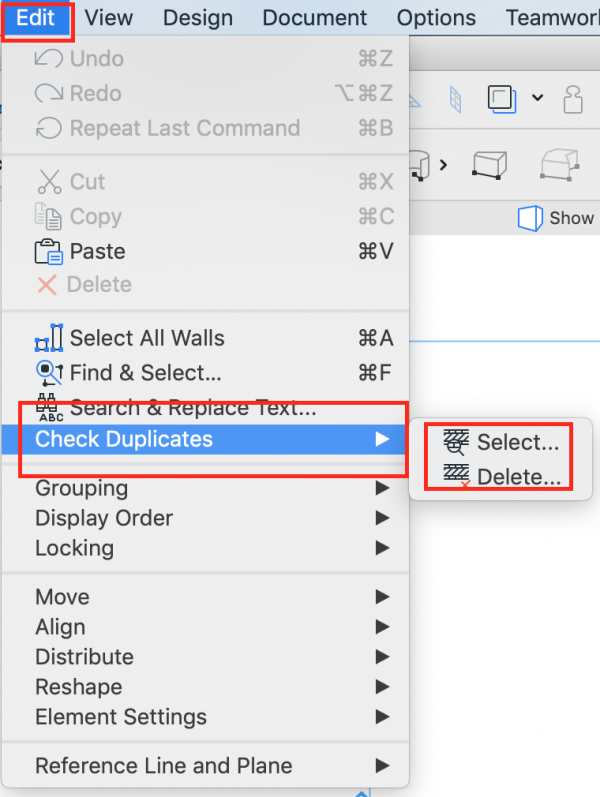
How To Check For Duplicates In Archicad 24 Youtube
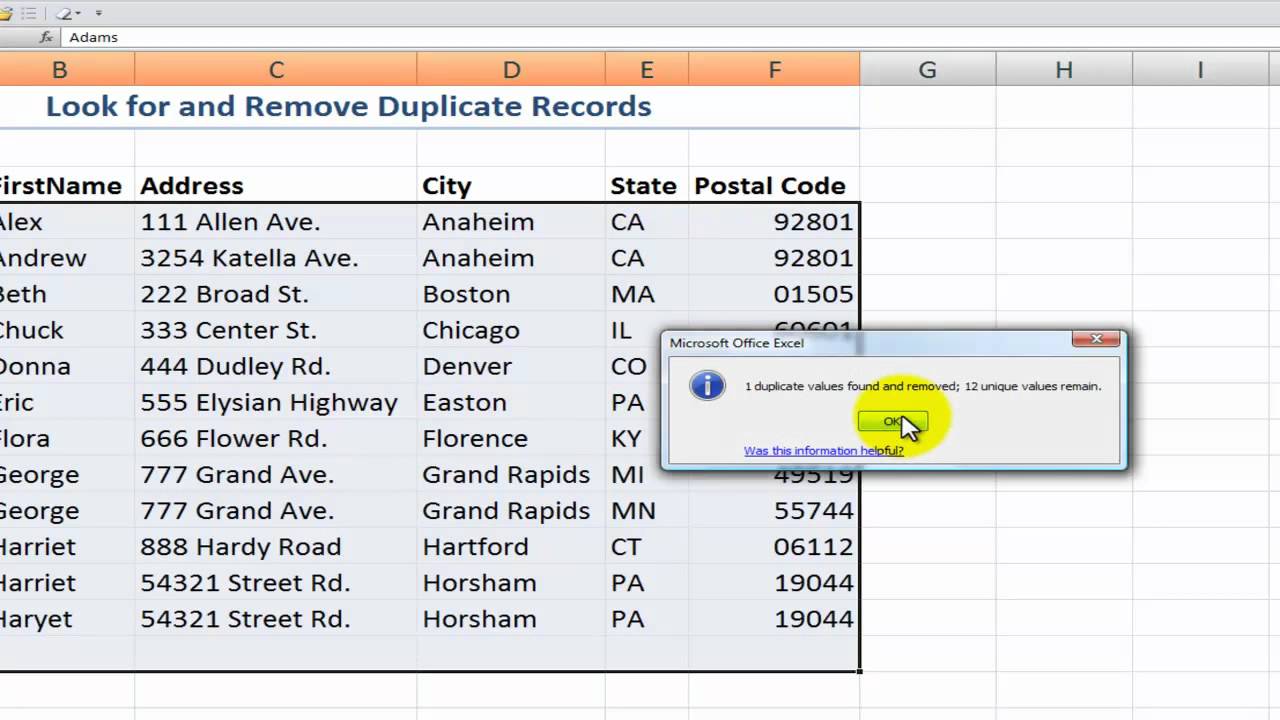
How To Find & Remove Duplicate Records In Excel 2007 Youtube
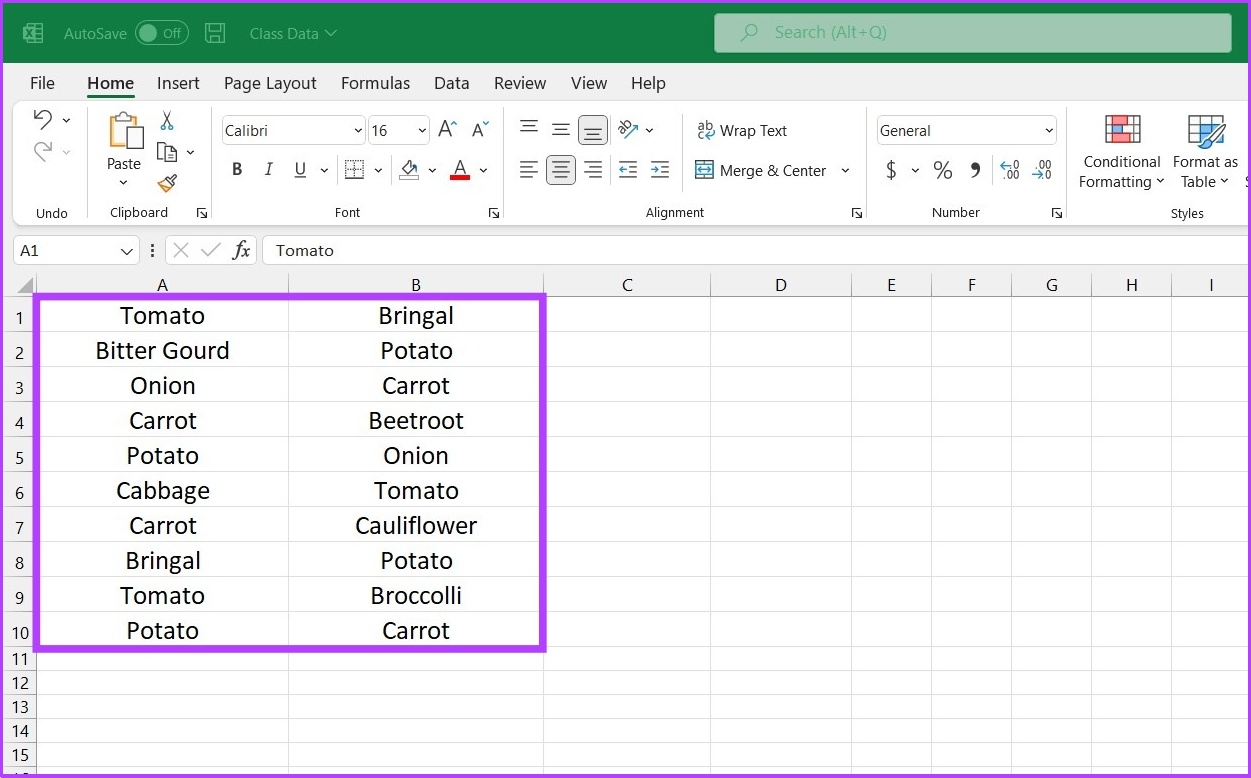
How To Highlight Duplicates In Excel 2 Easy Ways Guiding Tech

How To Check Duplicate In Oracle Table
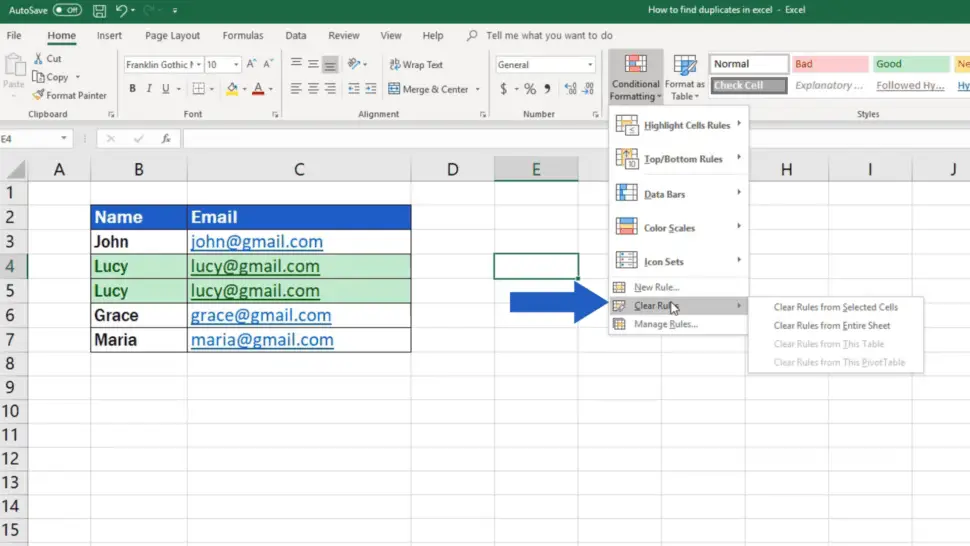
How To Find Duplicates In Excel